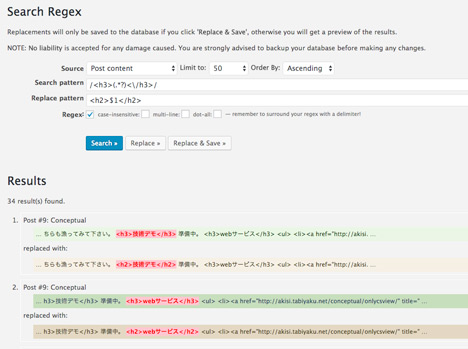
twigの実践編というわけでもないが、これまでConceptualのページに載せていたWEBサービスページの共通部分(ヘッダー、広告、フッターなど)をtwigテンプレートとして抽出する作業を行ったので、その過程など紹介してみようと思う。
共通部分の抽出
公開しているプログラムのうち、OnlyCSViewとEXIFviewerについてはページ構造がほぼ同じだ。現在の2プログラムの画面を並べてみると、下の画像のような感じになる。共通部分と書いてある所はほぼソースが同じであり、真ん中の白い部分(コントローラ部分)とスクリプトの部分だけが違うということになる。
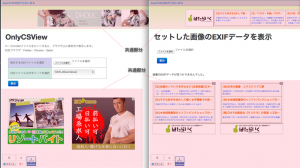
共通部分を持つ2ページ
テンプレートエンジンで共通部分を抽出する場合、Smarty2.xのような”閉じhead前切り”パラダイムのものだと、ヘッダー部分、メイン部分、フッター部分と必要ファイルが3つになってしまうだろう。今回はテンプレートの継承機能のあるTwigを用いるため、ヘッダーとフッターを含んだ基礎部分のテンプレート(base.html.twig)にメイン部分に対応するブロックを作り、子テンプレートでブロック部分をオーバーライドするという、2ファイルでの解決を図ることにする。
ロジックとビューの分離
加えて、今回手を入れるプログラムは相当昔に作ったものなので、PHP入門書の最初のサンプルにありがちな、ロジックとビューが混在している状態になっている。テンプレートエンジンらしく、これの分離も同時に行ってみたい。
EXIFviewer手入れ前のソース
ロジックとビューの分離の説明に丁度良かったので、今回例として出すのはEXIFviewerの方にする。
//手入れ前index.php(1ファイル)
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<meta name="Description" content="EXIFviewerはローカルのJPEGファイルをアップロードすることなくサイズ、位置情報、撮影情報等のEXIFデータを確認できるWEBサービスです。">
<meta name="Keywords" content="PHP,EXIF,WEBサービス,JPEG,画像,位置情報">
<link rel="stylesheet" href="base.css" type="text/css">
.
.
<script>
$(function(){
$("#filesel").change(function(){
var reader = new FileReader();
reader.readAsDataURL(document.getElementById("filesel").files[0]);
reader.onload = function(e){
$("#path").val(e.target.result);
}
if(window.createObjectURL){
var ourl = window.createObjectURL(document.getElementById("filesel").files[0]);
} else if(window.URL) {
var ourl = window.URL.createObjectURL(document.getElementById("filesel").files[0]);
} else {
var ourl = window.webkitURL.createObjectURL(document.getElementById("filesel").files[0]);
}
$("#viewer").empty().html('<img src="' + ourl + '">');
$("#blob").val(ourl);
});//end of fileselchange
//Googlemap関連コード(省略)
});//end of jQueryready
</script>
<title>EXIFviewer JPEGファイルのEXIF情報をチェックするWEBサービス</title>
.
.
</head>
<body>
<div id="main">
<nav><div id="back"><a href="http://akisi.tabiyaku.net/" title="AkisiのWEB制作日記に戻る">AkisiのWEB制作日記に戻る</a></div></nav>
<div id="upperad">
<script type="text/javascript">
//adsenseコード
</script>
</div>
<div id="instruction">
<h1>セットした画像のEXIFデータを表示</h1>
</div>
<div id="controlls">
<form>
<p><input type="file" id="filesel" type="image/jpeg"></p>
</form>
<form action="index.php" method="post">
<div id = "viewer">
<?php
if(!empty($_POST["path"])){
echo '<img src="' . $_POST["path"] . '">';
}
?>
</div>
<input type="hidden" name="blob" id ="blob">
<input type="hidden" name="path" id ="path">
<p><input type="submit" value="表示" class="btn btn-primary"></p>
</form>
</div>
<div id="tablearea">
<?php
if(!empty($_POST["blob"])){
if($exif = exif_read_data($_POST["blob"],NULL,true)){
echo "<h2>EXIF情報</h2>";
echo "<table class='exiftable table table-striped'><thead><tr><th>キー名</th><th>値</th></tr></thead><tbody>";
foreach ($exif as $key => $section) {
foreach ($section as $name => $val) {
if(is_array($val)){
foreach ($val as $valname => $vval) {
echo "<tr><td>" . htmlentities($key,ENT_QUOTES,"UTF-8") . ' ' . htmlentities($name,ENT_QUOTES,"UTF-8") . ' ' . htmlentities($valname,ENT_QUOTES,"UTF-8") . "</td><td id=" . '"' . htmlentities($name . $valname,ENT_QUOTES,"UTF-8") . '">' . "$vval</td></tr>";
}
} else {
echo "<tr><td>" . htmlentities($key,ENT_QUOTES,"UTF-8") . ' ' . htmlentities($name,ENT_QUOTES,"UTF-8") . "</td><td id=" . '"' . htmlentities($name,ENT_QUOTES,"UTF-8") . '">' . htmlentities($val,ENT_QUOTES,"UTF-8") . "</td></tr>";
}
}
}
echo "</tbody></table>";
} else {
echo "画像のEXIFデータが見つかりませんでした。";
}
} else {
echo "画像のEXIFデータが見つかりませんでした。";
}
?>
</div>
<div id="googlemapdivarea">
<div id="googlemapdiv"></div>
</div>
<div id="lowerad">
<div class="loweradbox">
<script>
//adsenseコード
</script>
</div>
<div class="loweradbox">
<script>
//adsenseコード
</script>
</div>
</div>
</div>
</body>
</html> |
//手入れ前index.php(1ファイル)
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<meta name="Description" content="EXIFviewerはローカルのJPEGファイルをアップロードすることなくサイズ、位置情報、撮影情報等のEXIFデータを確認できるWEBサービスです。">
<meta name="Keywords" content="PHP,EXIF,WEBサービス,JPEG,画像,位置情報">
<link rel="stylesheet" href="base.css" type="text/css">
.
.
<script>
$(function(){
$("#filesel").change(function(){
var reader = new FileReader();
reader.readAsDataURL(document.getElementById("filesel").files[0]);
reader.onload = function(e){
$("#path").val(e.target.result);
}
if(window.createObjectURL){
var ourl = window.createObjectURL(document.getElementById("filesel").files[0]);
} else if(window.URL) {
var ourl = window.URL.createObjectURL(document.getElementById("filesel").files[0]);
} else {
var ourl = window.webkitURL.createObjectURL(document.getElementById("filesel").files[0]);
}
$("#viewer").empty().html('<img src="' + ourl + '">');
$("#blob").val(ourl);
});//end of fileselchange
//Googlemap関連コード(省略)
});//end of jQueryready
</script>
<title>EXIFviewer JPEGファイルのEXIF情報をチェックするWEBサービス</title>
.
.
</head>
<body>
<div id="main">
<nav><div id="back"><a href="http://akisi.tabiyaku.net/" title="AkisiのWEB制作日記に戻る">AkisiのWEB制作日記に戻る</a></div></nav>
<div id="upperad">
<script type="text/javascript">
//adsenseコード
</script>
</div>
<div id="instruction">
<h1>セットした画像のEXIFデータを表示</h1>
</div>
<div id="controlls">
<form>
<p><input type="file" id="filesel" type="image/jpeg"></p>
</form>
<form action="index.php" method="post">
<div id = "viewer">
<?php
if(!empty($_POST["path"])){
echo '<img src="' . $_POST["path"] . '">';
}
?>
</div>
<input type="hidden" name="blob" id ="blob">
<input type="hidden" name="path" id ="path">
<p><input type="submit" value="表示" class="btn btn-primary"></p>
</form>
</div>
<div id="tablearea">
<?php
if(!empty($_POST["blob"])){
if($exif = exif_read_data($_POST["blob"],NULL,true)){
echo "<h2>EXIF情報</h2>";
echo "<table class='exiftable table table-striped'><thead><tr><th>キー名</th><th>値</th></tr></thead><tbody>";
foreach ($exif as $key => $section) {
foreach ($section as $name => $val) {
if(is_array($val)){
foreach ($val as $valname => $vval) {
echo "<tr><td>" . htmlentities($key,ENT_QUOTES,"UTF-8") . ' ' . htmlentities($name,ENT_QUOTES,"UTF-8") . ' ' . htmlentities($valname,ENT_QUOTES,"UTF-8") . "</td><td id=" . '"' . htmlentities($name . $valname,ENT_QUOTES,"UTF-8") . '">' . "$vval</td></tr>";
}
} else {
echo "<tr><td>" . htmlentities($key,ENT_QUOTES,"UTF-8") . ' ' . htmlentities($name,ENT_QUOTES,"UTF-8") . "</td><td id=" . '"' . htmlentities($name,ENT_QUOTES,"UTF-8") . '">' . htmlentities($val,ENT_QUOTES,"UTF-8") . "</td></tr>";
}
}
}
echo "</tbody></table>";
} else {
echo "画像のEXIFデータが見つかりませんでした。";
}
} else {
echo "画像のEXIFデータが見つかりませんでした。";
}
?>
</div>
<div id="googlemapdivarea">
<div id="googlemapdiv"></div>
</div>
<div id="lowerad">
<div class="loweradbox">
<script>
//adsenseコード
</script>
</div>
<div class="loweradbox">
<script>
//adsenseコード
</script>
</div>
</div>
</div>
</body>
</html>
いわゆる、初回アクセス時にはPOSTの値(”blob”と”path”)が空であるため例外処理として初期画面を吐いているタイプのページだ。1ファイルでまとまってくれているので扱い易いが、echo命令によってテーブルを構成するhtmlタグの細切れを吐いている部分は一見して訳が分からない。html修正時にミスも起こり易いだろう。
EXIFviewer手入れ後のソース
index.phpにはテンプレートの呼び出しとロジックを押し込み、base.html.twigとindex.html.twigの2ファイルに値だけ渡す。
//index.php
require_once("Twig/Autoloader.php");
Twig_Autoloader::register();
$loader = new Twig_Loader_Filesystem("twigtmp/");
$twig = new Twig_Environment($loader, array("cache" => "cache/"));
$blob = "";
$exif = array();
if(isset($_POST["blob"])){
$blob = $_POST["blob"];
}
if(!empty($_POST["path"])){
$exif = exif_read_data($_POST["path"],NULL,true);
}
$page = array(
"description" => "EXIFviewerはローカルのJPEGファイルをアップロードすることなくサイズ、位置情報、撮影情報等のEXIFデータを確認できるWEBサービスです。",
"keywords" => "PHP,EXIF,WEBサービス,JPEG,画像,位置情報",
"title" => "EXIFviewer JPEGファイルのEXIF情報をチェックするWEBサービス",
"blob" => $blob,
"exif" => $exif
);
$template = $twig->loadTemplate("index.html.twig");
$template->display($page); |
//index.php
require_once("Twig/Autoloader.php");
Twig_Autoloader::register();
$loader = new Twig_Loader_Filesystem("twigtmp/");
$twig = new Twig_Environment($loader, array("cache" => "cache/"));
$blob = "";
$exif = array();
if(isset($_POST["blob"])){
$blob = $_POST["blob"];
}
if(!empty($_POST["path"])){
$exif = exif_read_data($_POST["path"],NULL,true);
}
$page = array(
"description" => "EXIFviewerはローカルのJPEGファイルをアップロードすることなくサイズ、位置情報、撮影情報等のEXIFデータを確認できるWEBサービスです。",
"keywords" => "PHP,EXIF,WEBサービス,JPEG,画像,位置情報",
"title" => "EXIFviewer JPEGファイルのEXIF情報をチェックするWEBサービス",
"blob" => $blob,
"exif" => $exif
);
$template = $twig->loadTemplate("index.html.twig");
$template->display($page);
続いて呼ばれる側のテンプレート2ファイル(実際名指しされるのはindex.html.twigの方だけだけれど)。
<!-- base.html.twig -->
<!doctype html>
<html>
<head>
<meta charset="UTF-8">
<link rel="stylesheet" href="css/base.css" type="text/css">
{% if description is not empty %}
<meta name="description" content="{{ description }}">
{% else %}
<meta name="description" content="AkisiのWEB制作日記の提供するウェブサービス">
{% endif %}
{% if keywords is not empty %}
<meta name="keywords" content="{{ keywords }}">
{% else %}
<meta name="keywords" content="ウェブサービス,WEB">
{% endif %}
.
.
<title>{{ title }}</title>
{% block head %}
{% endblock head %}
.
.
</head>
<body>
<div id="main">
<nav><div id="back"><a href="http://akisi.tabiyaku.net/" title="AkisiのWEB制作日記に戻る">AkisiのWEB制作日記に戻る</a></div></nav>
<div id="upperad">
<script>
//adsenseコード
</script>
</div>
{% block main %}
{% endblock main %}
<div id="lowerad">
<div class="loweradbox">
<script>
//adsenseコード
</script>
</div>
<div class="loweradbox">
<script>
//adsenseコード
</script>
</div>
</div>
</div>
</body>
</html>
<!-- index.html.twig -->
{% extends "base.html.twig" %}
{% block head %}
<link rel="stylesheet" href="css/index.css" type="text/css">
<script type="text/javascript" src="https://maps.googleapis.com/maps/api/js?v=3.exp&sensor=false"></script>
<script type="text/javascript">
$(function(){
$("#filesel").change(function(){
var reader = new FileReader();
reader.readAsDataURL(document.getElementById("filesel").files[0]);
reader.onload = function(e){
$("#path").val(e.target.result);
}
if(window.createObjectURL){
var ourl = window.createObjectURL(document.getElementById("filesel").files[0]);
} else if(window.URL) {
var ourl = window.URL.createObjectURL(document.getElementById("filesel").files[0]);
} else {
var ourl = window.webkitURL.createObjectURL(document.getElementById("filesel").files[0]);
}
$("#viewer").empty().html('<img src="' + ourl + '">');
$("#blob").val(ourl);
});//end of fileselchange
//Googlemap関連コード(省略)
});//end of jQueryready
</script>
{% endblock head %}
{% block main %}
<div id="instruction">
<h1>セットした画像のEXIFデータを表示</h1>
</div>
<div id="controlls">
<form>
<p><input type="file" id="filesel" type="image/jpeg"></p>
</form>
<form action="index.php" method="post">
<div id = "viewer">
{% if blob is not empty %}
<img src="{{ blob }}">
{% endif %}
</div>
<input type="hidden" name="blob" id ="blob">
<input type="hidden" name="path" id ="path">
<p>
<span><input type="submit" value="表示" class="btn btn-primary"></span>
</p>
</form>
</div>
<div id="tablearea">
{% if exif is not empty %}
<h2>EXIF情報</h2>
<table class='exiftable table table-striped'><thead><tr><th>キー名</th><th>値</th></tr></thead><tbody>
{% for key, section in exif %}
{% for name, val in section %}
{% if val is iterable %}
{% for valname, vval in val %}
<tr><td>{{ key }} {{ name }} {{ valname }}</td><td id="{{ name }}{{ valname }}">{{ vval }}</td></tr>
{% endfor %}
{% else %}
<tr><td>{{ key }} {{ name }}</td><td id="{{ name }}">{{ val }}</td></tr>
{% endif %}
{% endfor %}
{% endfor %}
</tbody></table>
{% else %}
画像のEXIFデータが見つかりませんでした。
{% endif %}
</div>
<div id="googlemapdivarea">
<div id="googlemapdiv"></div>
</div>
{% endblock main %} |
<!-- base.html.twig -->
<!doctype html>
<html>
<head>
<meta charset="UTF-8">
<link rel="stylesheet" href="css/base.css" type="text/css">
{% if description is not empty %}
<meta name="description" content="{{ description }}">
{% else %}
<meta name="description" content="AkisiのWEB制作日記の提供するウェブサービス">
{% endif %}
{% if keywords is not empty %}
<meta name="keywords" content="{{ keywords }}">
{% else %}
<meta name="keywords" content="ウェブサービス,WEB">
{% endif %}
.
.
<title>{{ title }}</title>
{% block head %}
{% endblock head %}
.
.
</head>
<body>
<div id="main">
<nav><div id="back"><a href="http://akisi.tabiyaku.net/" title="AkisiのWEB制作日記に戻る">AkisiのWEB制作日記に戻る</a></div></nav>
<div id="upperad">
<script>
//adsenseコード
</script>
</div>
{% block main %}
{% endblock main %}
<div id="lowerad">
<div class="loweradbox">
<script>
//adsenseコード
</script>
</div>
<div class="loweradbox">
<script>
//adsenseコード
</script>
</div>
</div>
</div>
</body>
</html>
<!-- index.html.twig -->
{% extends "base.html.twig" %}
{% block head %}
<link rel="stylesheet" href="css/index.css" type="text/css">
<script type="text/javascript" src="https://maps.googleapis.com/maps/api/js?v=3.exp&sensor=false"></script>
<script type="text/javascript">
$(function(){
$("#filesel").change(function(){
var reader = new FileReader();
reader.readAsDataURL(document.getElementById("filesel").files[0]);
reader.onload = function(e){
$("#path").val(e.target.result);
}
if(window.createObjectURL){
var ourl = window.createObjectURL(document.getElementById("filesel").files[0]);
} else if(window.URL) {
var ourl = window.URL.createObjectURL(document.getElementById("filesel").files[0]);
} else {
var ourl = window.webkitURL.createObjectURL(document.getElementById("filesel").files[0]);
}
$("#viewer").empty().html('<img src="' + ourl + '">');
$("#blob").val(ourl);
});//end of fileselchange
//Googlemap関連コード(省略)
});//end of jQueryready
</script>
{% endblock head %}
{% block main %}
<div id="instruction">
<h1>セットした画像のEXIFデータを表示</h1>
</div>
<div id="controlls">
<form>
<p><input type="file" id="filesel" type="image/jpeg"></p>
</form>
<form action="index.php" method="post">
<div id = "viewer">
{% if blob is not empty %}
<img src="{{ blob }}">
{% endif %}
</div>
<input type="hidden" name="blob" id ="blob">
<input type="hidden" name="path" id ="path">
<p>
<span><input type="submit" value="表示" class="btn btn-primary"></span>
</p>
</form>
</div>
<div id="tablearea">
{% if exif is not empty %}
<h2>EXIF情報</h2>
<table class='exiftable table table-striped'><thead><tr><th>キー名</th><th>値</th></tr></thead><tbody>
{% for key, section in exif %}
{% for name, val in section %}
{% if val is iterable %}
{% for valname, vval in val %}
<tr><td>{{ key }} {{ name }} {{ valname }}</td><td id="{{ name }}{{ valname }}">{{ vval }}</td></tr>
{% endfor %}
{% else %}
<tr><td>{{ key }} {{ name }}</td><td id="{{ name }}">{{ val }}</td></tr>
{% endif %}
{% endfor %}
{% endfor %}
</tbody></table>
{% else %}
画像のEXIFデータが見つかりませんでした。
{% endif %}
</div>
<div id="googlemapdivarea">
<div id="googlemapdiv"></div>
</div>
{% endblock main %}
テンプレートのcssは、共通部分のためのbase.cssと、index.cssに分ける。手入れ前のソースでは色付きハイライトされているPHP部分がなくなり、その代わりにtwigのfor inで配列を回している。テンプレート関係で新しく登場したのは、for inで回す際にキー値にもアクセスする場合の、{% for key, value in array %}という書き方。それから、配列に要素があるかどうか調べるのには{% if array is iterable %}のように書く、といったことくらいだろうか。
テンプレートの使い分け判断に使う値が変数の中にあるようであれば(あるいは変数自身の存在で判断できるのであれば)変数のみをそのままテンプレートに渡し、そうでないようならロジック側で切り替え判断のためのフラグを値で用意し、変数とフラグを合わせてテンプレートに渡す、このようにしてロジックとビューの分離をはかるわけである。
あとは、テンプレート中のJavaScriptに波括弧が含まれる場合{% raw %}{% endraw %}で囲むのを忘れずに。
TwigをLinuxの公開サーバに上げる段になってハマり易いこと
Twigで個人的にハマったこと。MAMPなどのローカル環境で動作したプログラムを公開サーバにアップロードしてみると、以下のようなエラーが出て動かないということがあった。
Class ‘Twig_Loader_Filesystem’ not found
原因は、ざっくり言ってしまうとLinuxが大文字小文字の扱いにうるさいからだった。たとえばAutoloader.phpへのパスが”twig/Twig/Autoloader.php”だった場合、”Twig/Twig/Autoloader.php”というように指定してしまうと、OSXやWindowsなどの環境では理解してくれるものの、Linuxサーバ上では理解をしてくれない。
また、Autoloader.phpの上位のディレクトリ名も、”Twig”でないといけない。思う所あって”twig”というように小文字のディレクトリにしてアップロードしていたから、”twig/Autoloader.php”という正しいパスを指定してもエラーが出てしまっていることに当惑した。”Twig”ディレクトリは勝手にリネームしてはいけない。それが今回の失敗の教訓。